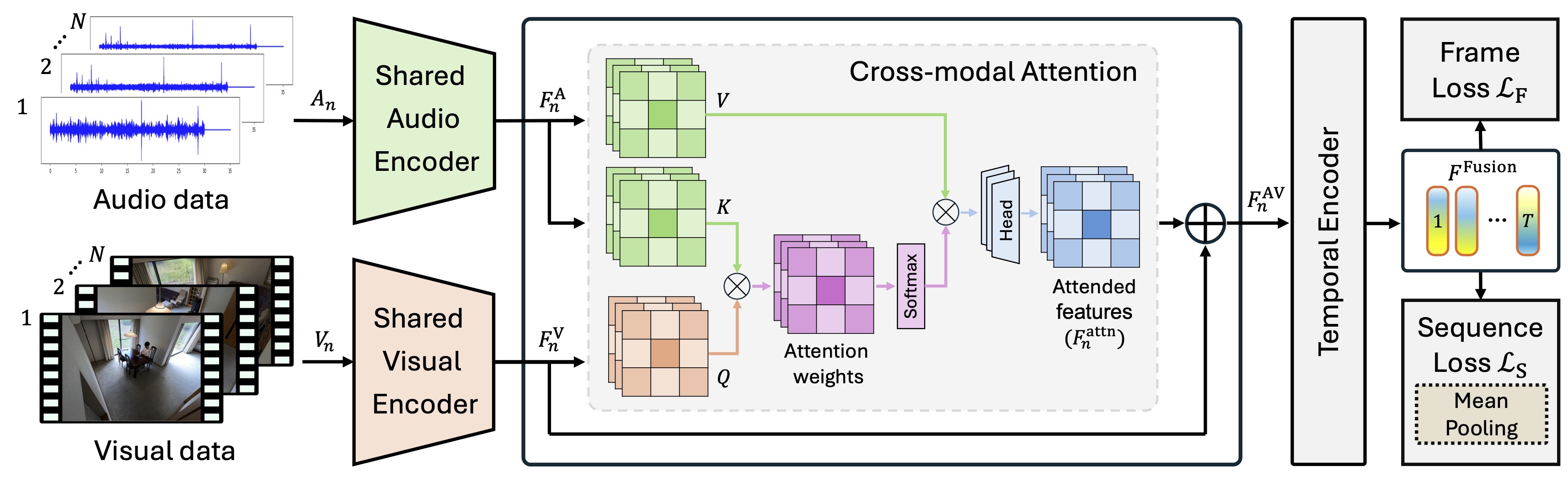
Multi-view action recognition is a critical task in computer vision, with broad applications in surveillance, robotics, and video-content analysis. Traditional single-view action recognition approaches suffer from a limited field of view and occlusion, leading to incomplete understanding of actions and a higher likelihood of misclassification. Moreover, most existing methods rely on constrained environments with strong label annotations, where the onset and offset times of each action are meticulously labeled at the frame-level. However, annotating strong labels for multi-view video sequences in real-world scenarios is time consuming and labor intensive. In many cases, only a weak video-level (sequence-level) label is available, where only the action class label for the entire video sequence is provided. This limits the performance of accurate action recognition. To overcome this limitation, we propose Multi-modal Multi-view Action Selection Learning (MMASL), which integrates audio and video data to perform frame-level action recognition in large-area environments using sequence-level weak labels. The key components of MMASL include modality-specific Shared Audio Encoder and Shared Video Encoder, and an Action Selection Learning (ASL) mechanism. The encoder processes input data from multiple views by extracting and unifying features from audio and video modalities. Meanwhile, ASL dynamically selects relevant frames across views and filters out irrelevant information while focusing on critical action segments to enhance action recognition accuracy. By incorporating audio data with video data, MMASL improves recognition accuracy for visually ambiguous actions that are distinguishable through sound. Experiments in a real-world office environment using the MM-Office dataset demonstrate that MMASL outperforms state-of-the-art methods, achieving up to 8.81% improvement in mAP_C (Class-wise mean Average Precision) and 8.43% in mAP_S (Sample-wise mean Average Precision), highlighting the significance of multi-modal multi-view action recognition with ASL in real-world scenarios.
@article{Nguyen2025ACMTOMM,note={International-Journal},author={Nguyen, Trung Thanh and and Kawanishi, Yasutomo and John, Vijay and Komamizu, Takahiro and Ide, Ichiro},title={Action Selection Learning for Weakly Labeled Multi-modal Multi-view Action Recognition},journal={ACM Transactions on Multimedia Computing, Communications, and Applications},doi={10.1145/3744742},publisher={ACM},year={2026},}
ACM TOMM
Hierarchical Local-Global Fusion for One-stage Open-vocabulary Temporal Action Detection
Trung Thanh Nguyen, Yasutomo Kawanishi, Takahiro Komamizu, and 1 more author
ACM Transactions on Multimedia Computing, Communications, and Applications, 2026
Open-vocabulary Temporal Action Detection (Open-vocab TAD) extends the detection scope of Closed-vocabulary Temporal Action Detection (Closed-vocab TAD) to unseen action classes specified by vocabularies not included in the training data, within untrimmed video. Typical Open-vocab TAD methods adopt a two-stage approach that first proposes candidate action intervals and then identifies those actions. However, errors in the first stage can affect the subsequent stage and the final detection results. Moreover, conventional methods for temporal context analyses tend to focus solely on either global or local context. Focusing solely on the global context can lead to lack of momentary detail, making it difficult to distinguish one action from another. Conversely, focusing only on the local context makes it challenging to determine the start and end timings of action intervals. To address these challenges, we introduce a one-stage approach named Hierarchical Open-vocab TAD (HOTAD), consisting of two branches: Temporal Context Analysis (TCA) and Video-Text Alignment (VTA). The former utilizes Hierarchical Encoder (HE) to fuse global and local temporal features, enabling a comprehensive capture of temporal actions, while the latter branch exploits the synergy between visual and textual modalities for precisely detecting unseen actions in the Open-vocab setting. Experiments and in-depth analysis using the widely recognized datasets THUMOS14 and ActivityNet-1.3 are performed to show the effectiveness of the proposed method. The results highlight remarkable accuracy in detecting a wide range of unseen actions. Furthermore, the proposed method significantly reduces wrong labels and localizes action instances with high precision, showcasing its robustness in complex and dynamic video settings.
@article{nguyen2025_HOTAD,note={International-Journal},title={Hierarchical Local-Global Fusion for One-stage Open-vocabulary Temporal Action Detection},author={Nguyen, Trung Thanh and Kawanishi, Yasutomo and Komamizu, Takahiro and Ide, Ichiro},journal={ACM Transactions on Multimedia Computing, Communications, and Applications},year={2026},publisher={ACM},doi={10.1145/3773986},}
2024
IEEE Access
Zero-shot Pill-Prescription Matching with Graph Convolutional Network and Contrastive Learning
Trung Thanh Nguyen, Phi Le Nguyen, Yasutomo Kawanishi, and 2 more authors
Patients’ safety is paramount in the healthcare industry, and reducing medication errors is essential for improvement. A promising solution to this problem involves the development of automated systems capable of assisting patients in verifying their pill intake mistakes. This paper investigates a Pill-Prescription matching task that seeks to associate pills in a multi-pill photo with their corresponding names in the prescription. We specifically aim to overcome the limitations of existing pill detection methods when faced with unseen pills, a situation characteristic of zero-shot learning. We propose a novel method named Zero-PIMA (Zero-shot Pill-Prescription Matching), designed to match pill images with prescription names effectively, even for pills not included in the training dataset. Zero-PIMA is an end-to-end model that includes an object localization module to determine and extract features of pill images and a graph convolutional network to capture the spatial relationship of the pills’ text in the prescription. After that, we leverage the contrastive learning paradigm to increase the distance between mismatched pill images and pill name pairs while minimizing the distance between matched pairs. In addition, to deal with the zero-shot pill detection problem, we leverage pills’ metadata retrieved from the DrugBank database to fine-tune a pre-trained text encoder, thereby incorporating visual information about pills (e.g., shape, color) into their names, making them more informative and ultimately enhancing the pill image-name matching accuracy. Extensive experiments are conducted on our collected real-world VAIPE-PP dataset of multi-pill photos and prescriptions. Through a series of comprehensive experiments, the proposed method outperforms other methods for both seen and unseen pills in terms of mean average precision. These results indicate that the proposed method could reduce medication errors and improve patients’ safety.
@article{Nguyen2024IEEEAccess,note={International-Journal},author={Nguyen, Trung Thanh and Nguyen, Phi Le and Kawanishi, Yasutomo and Komamizu, Takahiro and Ide, Ichiro},title={Zero-shot Pill-Prescription Matching with Graph Convolutional Network and Contrastive Learning},journal={IEEE Access},publisher={IEEE},year={2024},doi={10.1109/ACCESS.2024.3390153},}
2022
IEEE TNSM
Fuzzy Q-Learning-Based Opportunistic Communication for MEC-Enhanced Vehicular Crowdsensing
Trung Thanh Nguyen, Truong Thao Nguyen, Thanh-Hung Nguyen, and 1 more author
IEEE Transactions on Network and Service Management, 2022
This study focuses on MEC-enhanced, vehicle-based crowdsensing systems that rely on devices installed on automobiles. We investigate an opportunistic communication paradigm in which devices can transmit measured data directly to a crowdsensing server over a 4G communication channel or to nearby devices or so-called Road Side Units positioned along the road via Wi-Fi. We tackle a new problem that is how to reduce the cost of 4G while preserving the latency. We propose an offloading strategy that combines a reinforcement learning technique known as Q-learning with Fuzzy logic to accomplish the purpose. Q-learning assists devices in learning to decide the communication channel. Meanwhile, Fuzzy logic is used to optimize the reward function in Q-learning. The experiment results show that our offloading method significantly cuts down around 30-40% of the 4G communication cost while keeping the latency of 99% packets below the required threshold.
@article{9841517,note={International-Journal},author={Nguyen, Trung Thanh and Thao Nguyen, Truong and Nguyen, Thanh-Hung and Nguyen, Phi Le},journal={IEEE Transactions on Network and Service Management},title={Fuzzy Q-Learning-Based Opportunistic Communication for MEC-Enhanced Vehicular Crowdsensing},year={2022},volume={19},number={4},pages={5021-5033},doi={10.1109/TNSM.2022.3192397},}
international conference
2026
IEEE/CVF WACV
View-aware Cross-modal Distillation for Multi-view Action Recognition
Trung Thanh Nguyen, Yasutomo Kawanishi, Vijay John, and 2 more authors
In Proceedings of the 2026 IEEE/CVF Winter Conference on Applications of Computer Vision, 2026
We proposed Q-Adapter as a highly parameter-efficient fine-tuning method for associating video information with textual information in the field of video captioning technology, which aims to describe video content in text form. We presented this work at the International Conference on Multimedia (MMAsia 2025). The proposed method was highly evaluated and received the Best Oral Award.
NeurIPS
Toward a Vision-Language Foundation Model for Medical Data: Multimodal Dataset and Benchmarks for Vietnamese PET/CT Report Generation
Huu Tien Nguyen, Dac Thai Nguyen, The Minh Duc Nguyen, and 11 more authors
In Proceedings of the 39th Conference on Neural Information Processing Systems, 2025
We presented a new multimodal, multi-view dataset called “MultiSensor-Home”, which provides high-resolution and fine-grained frame-level annotations for action recognition in wide-area distributed environments, along with a Transformer-based sensor fusion method called “MultiTSF”, at the international conference FG 2025, and received the Best Student Paper Award.
Multi-modal multi-view action recognition is a rapidly growing field in computer vision, offering significant potential for applications in surveillance. However, current datasets often fail to address real-world challenges such as wide-area distributed settings, asynchronous data streams, and the lack of frame-level annotations. Furthermore, existing methods face difficulties in effectively modeling inter-view relationships and enhancing spatial feature learning. In this paper, we introduce the MultiSensor-Home dataset, a novel benchmark designed for comprehensive action recognition in home environments, and also propose the Multi-modal Multi-view Transformer-based Sensor Fusion (MultiTSF) method. The proposed MultiSensor-Home dataset features untrimmed videos captured by distributed sensors, providing high-resolution RGB and audio data along with detailed multi-view frame-level action labels. The proposed MultiTSF method leverages a Transformer-based fusion mechanism to dynamically model inter-view relationships. Furthermore, the proposed method integrates a human detection module to enhance spatial feature learning, guiding the model to prioritize frames with human activity to enhance action the recognition accuracy. Experiments on the proposed MultiSensor-Home and the existing MM-Office datasets demonstrate the superiority of MultiTSF over the state-of-the-art methods. Quantitative and qualitative results highlight the effectiveness of the proposed method in advancing real-world multi-modal multi-view action recognition.
@inproceedings{nguyen2025multisensor,note={International-Conference},title={MultiSensor-Home: A Wide-area Multi-modal Multi-view Dataset for Action Recognition and Transformer-based Sensor Fusion},author={Nguyen, Trung Thanh and Kawanishi, Yasutomo and John, Vijay and Komamizu, Takahiro and Ide, Ichiro},booktitle={Proceedings of the 19th IEEE International Conference on Automatic Face and Gesture Recognition},year={2025},doi={10.1109/FG61629.2025.11099071},primaryclass={cs.CV},}
IEEE/CVF WACV
CT to PET Translation: A Large-scale Dataset and Domain-Knowledge-Guided Diffusion Approach
Dac Thai Nguyen, Trung Thanh Nguyen, Huu Tien Nguyen, and 5 more authors
In Proceedings of the 2025 IEEE/CVF Winter Conference on Applications of Computer Vision, 2025
Positron Emission Tomography (PET) and Computed Tomography (CT) are essential for diagnosing, staging, and monitoring various diseases, particularly cancer. Despite their importance, the use of PET/CT systems is limited by the necessity for radioactive materials, the scarcity of PET scanners, and the high cost associated with PET imaging. In contrast, CT scanners are more widely available and significantly less expensive. In response to these challenges, our study addresses the issue of generating PET images from CT images, aiming to reduce both the medical examination cost and the associated health risks for patients. Our contributions are twofold: First, we introduce a conditional diffusion model named CPDM, which, to our knowledge, is one of the initial attempts to employ a diffusion model for translating from CT to PET images. Second, we provide the largest CT-PET dataset to date, comprising 2,028,628 paired CT-PET images, which facilitates the training and evaluation of CT-to-PET translation models. For the CPDM model, we incorporate domain knowledge to develop two conditional maps: the Attention map and the Attenuation map. The former helps the diffusion process focus on areas of interest, while the latter improves PET data correction and ensures accurate diagnostic information. Experimental evaluations across various benchmarks demonstrate that CPDM surpasses existing methods in generating high-quality PET images in terms of multiple metrics.
@inproceedings{Nguyen2025CTPET,note={International-Conference},author={Nguyen, Dac Thai and Nguyen, Trung Thanh and Nguyen, Huu Tien and Nguyen, Thanh Trung and Pham, Huy Hieu and Nguyen, Thanh Hung and Nguyen, Truong Thao and Nguyen, Phi Le},title={CT to PET Translation: A Large-scale Dataset and Domain-Knowledge-Guided Diffusion Approach},booktitle={Proceedings of the 2025 IEEE/CVF Winter Conference on Applications of Computer Vision},year={2025},publisher={IEEE},}
2024
ACM MMAsia
Action Selection Learning for Multi-label Multi-view Action Recognition
Trung Thanh Nguyen, Yasutomo Kawanishi, Takahiro Komamizu, and 1 more author
In Proceedings of the 6th ACM International Conference on Multimedia in Asia, 2024
Multi-label multi-view action recognition aims to recognize multiple concurrent or sequential actions from untrimmed videos captured by multiple cameras. Existing work has focused on multi-view action recognition in a narrow area with strong labels available, where the onset and offset of each action are labeled at the frame-level. This study focuses on real-world scenarios where cameras are distributed to capture a wide-range area with only weak labels available at the video-level. We propose a method named Multi-view Action Selection Learning (MultiASL), which leverages action selection learning to enhance view fusion by selecting the most useful information from different viewpoints. The proposed method includes a Multi-view Spatial-Temporal Transformer video encoder to extract spatial and temporal features from multi-viewpoint videos. Action Selection Learning is employed at the frame-level, using pseudo ground-truth obtained from weak labels at the video-level, to identify the most relevant frames for action recognition. Experiments in a real-world office environment using the MM-Office dataset demonstrate the superior performance of the proposed method compared to existing methods.
@inproceedings{10.1145/3696409.3700211,note={International-Conference},author={Nguyen, Trung Thanh and Kawanishi, Yasutomo and Komamizu, Takahiro and Ide, Ichiro},title={Action Selection Learning for Multi-label Multi-view Action Recognition},year={2024},isbn={9798400712739},doi={10.1145/3696409.3700211},booktitle={Proceedings of the 6th ACM International Conference on Multimedia in Asia},}
IEEE NCA
FedMAC: Tackling Partial-Modality Missing in Federated Learning with Cross-Modal Aggregation and Contrastive Regularization
Manh Duong Nguyen, Trung Thanh Nguyen, Huy Hieu Pham, and 3 more authors
In Proceedings of the 22nd IEEE International Symposium on Network Computing and Applications, 2024
@inproceedings{Nguyen2024FedMAC,note={International-Conference},author={Nguyen, Manh Duong and Nguyen, Trung Thanh and Pham, Huy Hieu and Hoang, Trong Nghia and Nguyen, Phi Le and Huynh, Thanh Trung},title={FedMAC: Tackling Partial-Modality Missing in Federated Learning with Cross-Modal Aggregation and Contrastive Regularization},booktitle={Proceedings of the 22nd IEEE International Symposium on Network Computing and Applications},year={2024},publisher={IEEE},}
IEEE NCA
FedCert: Federated Accuracy Certification
Minh Hieu Nguyen, Huu Tien Nguyen, Trung Thanh Nguyen, and 4 more authors
In Proceedings of the 22nd IEEE International Symposium on Network Computing and Applications, 2024
@inproceedings{Nguyen2024FedCert,note={International-Conference},author={Nguyen, Minh Hieu and Nguyen, Huu Tien and Nguyen, Trung Thanh and Nguyen, Manh Duong and Hoang, Trong Nghia and Nguyen, Truong Thao and Nguyen, Phi Le},title={FedCert: Federated Accuracy Certification},booktitle={Proceedings of the 22nd IEEE International Symposium on Network Computing and Applications},year={2024},publisher={IEEE},}
IEEE FG
One-Stage Open-Vocabulary Temporal Action Detection Leveraging Temporal Multi-Scale and Action Label Features
Trung Thanh Nguyen, Yasutomo Kawanishi, Takahiro Komamizu, and 1 more author
In Proceedings of the 18th IEEE International Conference on Automatic Face and Gesture Recognition, 2024
Open-vocabulary Temporal Action Detection (Open-vocab TAD) is an advanced video analysis approach that expands Closed-vocabulary Temporal Action Detection (Closed-vocab TAD) capabilities. Closed-vocab TAD is typically confined to localizing and classifying actions based on a predefined set of categories. In contrast, Open-vocab TAD goes further and is not limited to these predefined categories. This is particularly useful in real-world scenarios where the variety of actions in videos can be vast and not always predictable. The prevalent methods in Open-vocab TAD typically employ a 2-stage approach, which involves generating action proposals and then identifying those actions. However, errors made during the first stage can adversely affect the subsequent action identification accuracy. Additionally, existing studies face challenges in handling actions of different durations owing to the use of fixed temporal processing methods. Therefore, we propose a 1-stage approach consisting of two primary modules: Multi-scale Video Analysis (MVA) and Video-Text Alignment (VTA). The MVA module captures actions at varying temporal resolutions, overcoming the challenge of detecting actions with diverse durations. The VTA module leverages the synergy between visual and textual modalities to precisely align video segments with corresponding action labels, a critical step for accurate action identification in Open-vocab scenarios. Evaluations on widely recognized datasets THUMOS14 and ActivityNet-1.3, showed that the proposed method achieved superior results compared to the other methods in both Open-vocab and Closed-vocab settings. This serves as a strong demonstration of the effectiveness of the proposed method in the TAD task.
@inproceedings{10581896,note={International-Conference},author={Nguyen, Trung Thanh and Kawanishi, Yasutomo and Komamizu, Takahiro and Ide, Ichiro},booktitle={Proceedings of the 18th IEEE International Conference on Automatic Face and Gesture Recognition},title={One-Stage Open-Vocabulary Temporal Action Detection Leveraging Temporal Multi-Scale and Action Label Features},year={2024},doi={10.1109/FG59268.2024.10581896},}
2022
PRICAI
A Novel Approach for Pill-Prescription Matching with GNN Assistance and Contrastive Learning
Trung Thanh Nguyen, Hoang Dang Nguyen, Thanh Hung Nguyen, and 3 more authors
In Proceedings of the 2022 Pacific Rim International Conference on Artificial Intelligence, 2022
@inproceedings{nguyen2022novel,note={International-Conference},title={A Novel Approach for Pill-Prescription Matching with GNN Assistance and Contrastive Learning},author={Nguyen, Trung Thanh and Nguyen, Hoang Dang and Nguyen, Thanh Hung and Pham, Huy Hieu and Ide, Ichiro and Nguyen, Phi Le},booktitle={Proceedings of the 2022 Pacific Rim International Conference on Artificial Intelligence},pages={261--274},year={2022},organization={Springer},doi={10.1007/978-3-031-20862-1_19},}
ICPP
FedDRL: Deep Reinforcement Learning-based Adaptive Aggregation for Non-IID Data in Federated Learning
Nang Hung Nguyen, Phi Le Nguyen, Thuy Dung Nguyen, and 5 more authors
In Proceedings of the 51st International Conference on Parallel Processing, 2022
@inproceedings{nguyen2022feddrl,note={International-Conference},title={FedDRL: Deep Reinforcement Learning-based Adaptive Aggregation for Non-IID Data in Federated Learning},author={Nguyen, Nang Hung and Nguyen, Phi Le and Nguyen, Thuy Dung and Nguyen, Trung Thanh and Nguyen, Duc Long and Nguyen, Thanh Hung and Pham, Huy Hieu and Truong, Thao Nguyen},booktitle={Proceedings of the 51st International Conference on Parallel Processing},year={2022},doi={10.1145/3545008.3545085},}
IEEE WCNC
Deep Reinforcement Learning-based Offloading for Latency Minimization in 3-tier V2X Networks
Hieu Dinh, Nang Hung Nguyen, Trung Thanh Nguyen, and 3 more authors
In Proceedings of the 2022 IEEE Wireless Communications and Networking Conference, 2022
@inproceedings{9771583,note={International-Conference},author={Dinh, Hieu and Nguyen, Nang Hung and Nguyen, Trung Thanh and Nguyen, Thanh Hung and Nguyen, Truong Thao and Le Nguyen, Phi},booktitle={Proceedings of the 2022 IEEE Wireless Communications and Networking Conference},title={Deep Reinforcement Learning-based Offloading for Latency Minimization in 3-tier V2X Networks},year={2022},pages={1803-1808},doi={10.1109/WCNC51071.2022.9771583}}
2021
KSE
Data Augmentation for Small Face Datasets and Face Verification by Generative Adversarial Networks Inversion
Dinh Tan Nguyen, Cao Truong Tran, Trung Thanh Nguyen, and 4 more authors
In Proceedings of the 13th International Conference on Knowledge and Systems Engineering, 2021
@inproceedings{9648720,note={International-Conference},author={Nguyen, Dinh Tan and Tran, Cao Truong and Nguyen, Trung Thanh and Hoang, Cao Bao and Luu, Van Phu and Nguyen, Ba Ngoc and Cheong, Pou Ian},booktitle={Proceedings of the 13th International Conference on Knowledge and Systems Engineering},title={Data Augmentation for Small Face Datasets and Face Verification by Generative Adversarial Networks Inversion},year={2021},pages={1-6},doi={10.1109/KSE53942.2021.9648720},}
IEEE IPCCC
Q-learning-based Opportunistic Communication for Real-time Mobile Air Quality Monitoring Systems
Trung Thanh Nguyen, Truong Thao Nguyen, Tuan Anh Nguyen Dinh, and 2 more authors
In Proceedings of the 2021 IEEE International Performance, Computing, and Communications Conference, 2021
We focus on real-time air quality monitoring systems that rely on devices installed on automobiles in this research. We investigate an opportunistic communication model in which devices can send the measured data directly to the air quality server through a 4G communication channel or via Wi-Fi to adjacent devices or the so-called Road Side Units deployed along the road. We aim to reduce 4G costs while assuring data latency, where the data latency is defined as the amount of time it takes for data to reach the server. We propose an offloading scheme that leverages Q-learning to accomplish the purpose. The experiment results show that our offloading method significantly cuts down around 40-50% of the 4G communication cost while keeping the latency of 99.5% packets smaller than the required threshold.
@inproceedings{9679398,note={International-Conference},author={Nguyen, Trung Thanh and Thao Nguyen, Truong and Nguyen Dinh, Tuan Anh and Nguyen, Thanh Hung and Nguyen, Phi Le},booktitle={Proceedings of the 2021 IEEE International Performance, Computing, and Communications Conference},title={Q-learning-based Opportunistic Communication for Real-time Mobile Air Quality Monitoring Systems},year={2021},doi={10.1109/IPCCC51483.2021.9679398},}
domestic journal/conference
2026
PRMU - Japan
視野が部分的に重複する多視点行動認識における視点整合性学習法
Trung Thanh Nguyen, Yasutomo Kawanishi, Takahiro Komamizu, and 1 more author
In Proceedings of the 2026 Pattern Recognition and Media Understanding, 2026
@inproceedings{Nguyen2026PRMU,note={Domestic-Conference},author={Nguyen, Trung Thanh and Kawanishi, Yasutomo and Komamizu, Takahiro and Ide, Ichiro},title={視野が部分的に重複する多視点行動認識における視点整合性学習法},booktitle={Proceedings of the 2026 Pattern Recognition and Media Understanding},year={2026}}
2025
MIRU - Japan
MultiSensor-Home: Benchmark for Multi-modal Multi-view Action Recognition in Home Environments
Trung Thanh Nguyen, Yasutomo Kawanishi, John Vijay, and 2 more authors
In Proceedings of the 28th Meeting on Image Recognition and Understanding, 2025
@inproceedings{Nguyen2025MIRU,note={Domestic-Conference},author={Nguyen, Trung Thanh and Kawanishi, Yasutomo and Vijay, John and Komamizu, Takahiro and Ide, Ichiro},title={MultiSensor-Home: Benchmark for Multi-modal Multi-view Action Recognition in Home Environments},booktitle={Proceedings of the 28th Meeting on Image Recognition and Understanding},year={2025}}
MIRU - Japan
Visual Adapter for Extracting Textually-related Features in Video Captioning
Junan Chen, Trung Thanh Nguyen, Takahiro Komamizu, and 1 more author
In Proceedings of the 28th Meeting on Image Recognition and Understanding, 2025
@inproceedings{ChenJ2025MIRU,note={Domestic-Conference},author={Chen, Junan and Nguyen, Trung Thanh and Komamizu, Takahiro and Ide, Ichiro},title={Visual Adapter for Extracting Textually-related Features in Video Captioning},booktitle={Proceedings of the 28th Meeting on Image Recognition and Understanding},year={2025}}
@inproceedings{Nguyen2025PRMU,note={Domestic-Conference},author={Nguyen, Trung Thanh and Kawanishi, Yasutomo and John, Vijay and Komamizu, Takahiro and Ide, Ichiro},title={広域多視点マルチモーダル行動認識のためのセンサ統合手法とMultiSensor-Homeデータセットの提案},booktitle={Proceedings of the 2025 Pattern Recognition and Media Understanding},year={2025},}
2024
PRMU - Japan
大域・局所特徴統合埋め込みに基づくオープン語彙時系列行動検出
Trung Thanh Nguyen, Yasutomo Kawanishi, Takahiro Komamizu, and 1 more author
In Proceedings of the 2024 Pattern Recognition and Media Understanding, 2024
@inproceedings{Nguyen2024PRMU,note={Domestic-Conference},author={Nguyen, Trung Thanh and Kawanishi, Yasutomo and Komamizu, Takahiro and Ide, Ichiro},title={大域・局所特徴統合埋め込みに基づくオープン語彙時系列行動検出},booktitle={Proceedings of the 2024 Pattern Recognition and Media Understanding},year={2024},}
2023
DBWS - Japan
医療分野におけるゼロショット錠剤‐処方箋対応付け
Trung Thanh Nguyen, Phi Le Nguyen, Yasutomo Kawanishi, and 2 more authors
In Proceedings of the 2023 Tokai-Kansai Database Workshop, 2023
To prevent medication intake errors, we proposed a method to match prescription images with photos of medication, associating the pills in the images with those listed in the prescription. The method was evaluated through participant voting and was awarded the Best Presentation Award.
@inproceedings{Nguyen2023DBWS,note={Domestic-Conference},author={Nguyen, Trung Thanh and Nguyen, Phi Le and Kawanishi, Yasutomo and Komamizu, Takahiro and Ide, Ichiro},title={医療分野におけるゼロショット錠剤‐処方箋対応付け},booktitle={Proceedings of the 2023 Tokai-Kansai Database Workshop},year={2023},}
MIRU - Japan
時間マルチスケール特徴と行動ラベル特徴によるオープンボキャブラリ行動区間認識
Trung Thanh Nguyen, Yasutomo Kawanishi, Takahiro Komamizu, and 1 more author
In Proceedings of the 26th Meeting on Image Recognition and Understanding, 2023
@inproceedings{Nguyen2023,note={Domestic-Conference},author={Nguyen, Trung Thanh and Kawanishi, Yasutomo and Komamizu, Takahiro and Ide, Ichiro},title={時間マルチスケール特徴と行動ラベル特徴によるオープンボキャブラリ行動区間認識},booktitle={Proceedings of the 26th Meeting on Image Recognition and Understanding},year={2023}}
IEICE - Japan
PiDP: 処方箋に対する GCN の対照学習に基づく錠剤検出
Trung Thanh Nguyen, Yasutomo Kawanishi, Takahiro Komamizu, and 1 more author
In Proceedings of the 2023 IEICE General Conference, 2023
@inproceedings{2023pidp,note={Domestic-Conference},title={PiDP: 処方箋に対する GCN の対照学習に基づく錠剤検出},author={Nguyen, Trung Thanh and Kawanishi, Yasutomo and Komamizu, Takahiro and Ide, Ichiro},booktitle={Proceedings of the 2023 IEICE General Conference},year={2023},organization={The Institute of Electronics, Information and Communication Engineers},}
2022
HUST
Tối ưu truyền tin trong mạng điện toán biên di động bằng tuận toán Fuzzy Q-learning
Trung Thanh Nguyen, Nang Hung Nguyen, Manh Cuong Dao, and 2 more authors
Scientific Research Student Conference, Hanoi University of Science and Technology, 2022
Ứng dụng công nghệ điện toán đám mây di động (MCC) và điện toán biên di động (MEC) để giảm tải tác vụ tính toán là hướng tiếp cận đầy hứa hẹn cho phép các ứng dụng yêu cầu độ trễ thấp có thể thực thi trên các phương tiện giao thông thông minh. Hầu hết các nghiên cứu về giảm tải hiện nay tập trung vào sử dụng một mô hình đơn nhất là MEC hoặc MCC. Trong báo cáo này, chúng tôi nghiên cứu việc sử dụng kết hợp các công nghệ trong một mạng giao thông thông minh ba tầng V2X, trong đó phương tiện giao thông có thể giảm tải các tác vụ tính toán bằng cả MEC và MCC. Cụ thể, chúng tôi xem xét các xác suất tối ưu để định tuyến truyền tải trên ba đường truyền tin bao gồm: V2I, V2N và I2N. Nghiên cứu của chúng tôi có các đóng góp chính: Thứ nhất, chúng tôi đề xuất mô hình toán học tính toán chính xác độ trễ xử lý của các tác vụ, và công thức tìm lời giải tối ưu để đạt được độ trễ tối thiểu. Thứ hai, chúng tôi đề xuất phương pháp tối ưu dựa trên giải thuật di truyền (GA). Thứ ba, nhận thấy yếu điểm của GA, chúng tôi đề xuất một giải thuật ứng dụng kỹ thuật học tăng cường: multi-agent multi-armed bandits (MAB) với cải tiến cơ chế khám phá dựa trên hàm Sigmoid (SEM) để tối thiểu hóa độ trễ. Kết quả thí nghiệm cho thấy rằng thuật toán GA chúng tôi đề xuất trong mô hình ba tầng có thể rút ngắn độ trễ lên đến 99,9% so với các mô hình hai tầng hiện có, cơ chế khám phá cải tiến SEM chúng tôi đề xuất có độ trễ các tác vụ trung bình giảm 35% so với MAB cơ bản, thí nghiệm cũng cho thấy thuật toán MAB cải tiến rút ngắn độ trễ với trung bình 18.5% và 56.9% trong trường hợp tốt nhất so với thuật toán GA.
@article{JSTIC2021,note={Domestic-Journal},title={Mô hình mạng giao thông thông minh ba tầng và giải pháp giảm thiểu độ trễ truyền tin ứng dụng phương pháp học tăng cường},author={Nguyen, Nang Hung and Nguyen, Trung Thanh and Pham, Minh Khiem and Dinh, Van Hieu and Nguyen Dinh, Tuan Anh and Nguyen, Thanh Hung and Nguyen, Phi Le},year={2021},journal={Journal of Science and Technology on Information and Communications},}
HUST
Mô hình mạng giao thông thông minh ba tầng và giải pháp giảm thiểu độ trễ truyền tin ứng dụng phương pháp học tăng cường
Minh Khiem Pham, Nang Hung Nguyen, Trung Thanh Nguyen, and 2 more authors
Scientific Research Student Conference, Hanoi University of Science and Technology, 2021
This thesis was awarded the Best Thesis Award by the School of Information and Communications Technology, Hanoi University of Science and Technology, Vietnam.
miscellaneous (article, arXiv, etc.)
2025
arXiv
MultiTSF: Transformer-based Sensor Fusion for Human-Centric Multi-view and Multi-modal Action Recognition
Trung Thanh Nguyen, Yasutomo Kawanishi, Vijay John, and 2 more authors




 View-aware Cross-modal Distillation for Multi-view Action RecognitionIn Proceedings of the 2026 IEEE/CVF Winter Conference on Applications of Computer Vision, 2026
View-aware Cross-modal Distillation for Multi-view Action RecognitionIn Proceedings of the 2026 IEEE/CVF Winter Conference on Applications of Computer Vision, 2026
 IntentVC 2025: The ACM Multimedia Grand Challenge on Intention-Oriented Controllable Video CaptioningIn Proceedings of the 33rd ACM International Conference on Multimedia (Grand Challenge), 2025
IntentVC 2025: The ACM Multimedia Grand Challenge on Intention-Oriented Controllable Video CaptioningIn Proceedings of the 33rd ACM International Conference on Multimedia (Grand Challenge), 2025




