Automated instance segmentation of forest LiDAR point clouds is increasingly critical as forest monitoring moves toward scalable, detailed, 3D measurement. Yet progress is constrained by label scarcity for tree instances: a single hectare can hold millions of points and hundreds of overlapping, complex crowns, making manual annotation laborious and error-prone.
Inspired by the promptable paradigm of foundation segmentation models, we propose SelectAnyTree, a promptable instance segmentation model that delineates any individual tree in a 3D forest point cloud from a few clicks. SelectAnyTree introduces two key components: a click-to-query prompt encoder and a Canopy Height Model (CHM)-guided first prompt. The former turns each click into a single content query, encoding its 3D position and positive/negative polarity together with a pooled local backbone feature. The CHM provides treetops as a geometry- and ecologically-guided first prompt without any user input.
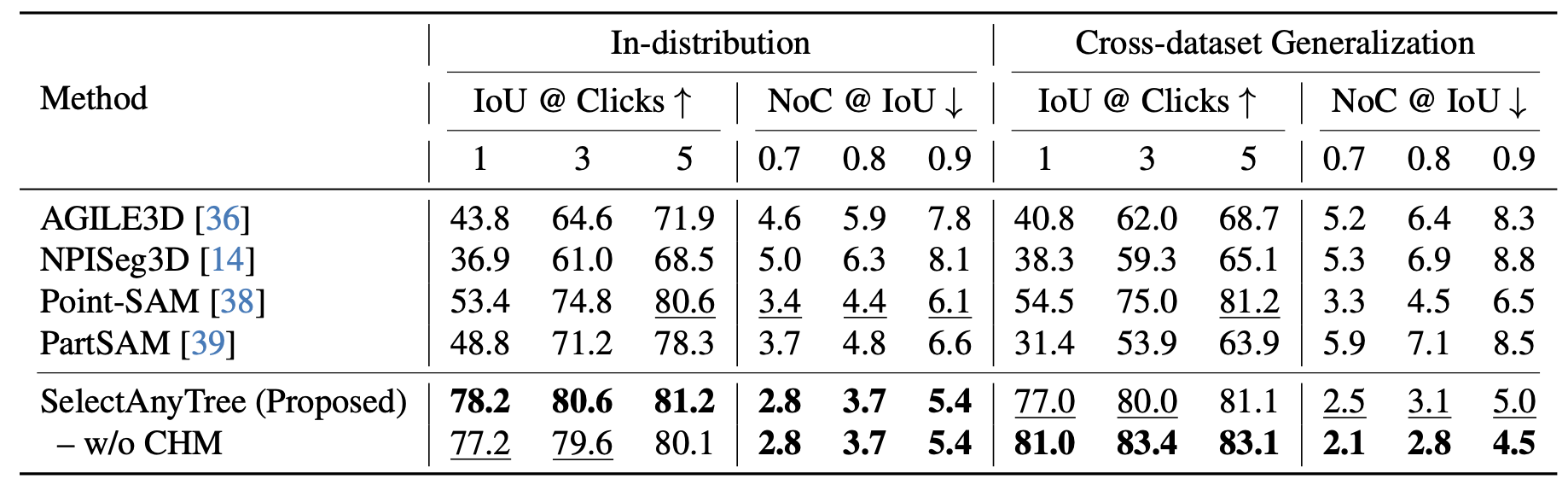
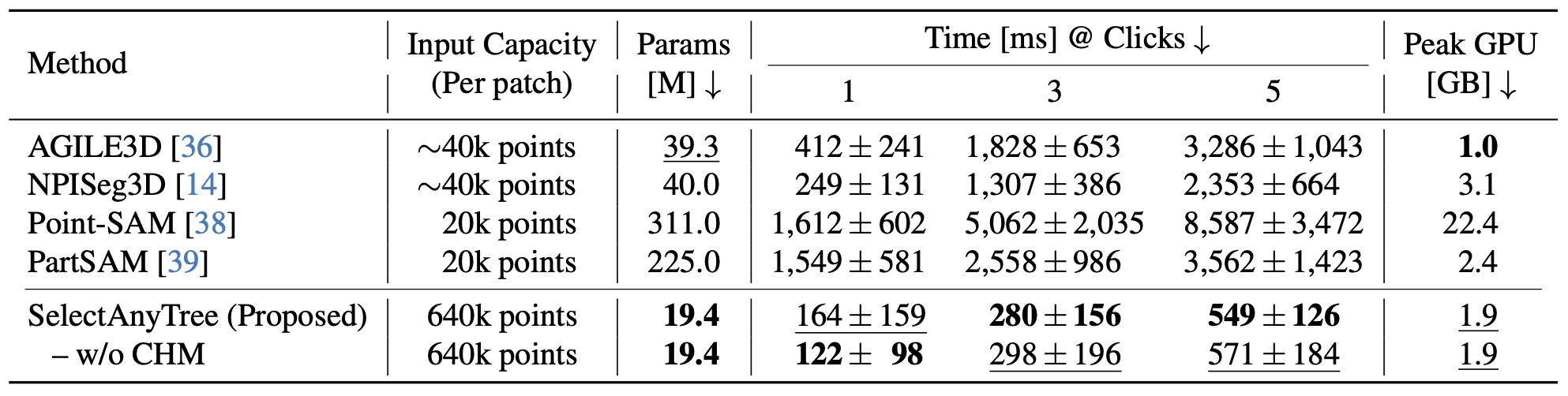
We evaluate SelectAnyTree across seven diverse forest regions and an independent held-out test dataset, demonstrating strong generalization beyond the training domains. It segments a target tree to 78.2 IoU from a single click — 24.8 points above the strongest promptable baseline — and reaches every accuracy target with the fewest clicks, while using far fewer parameters and less inference time than prior promptable models.
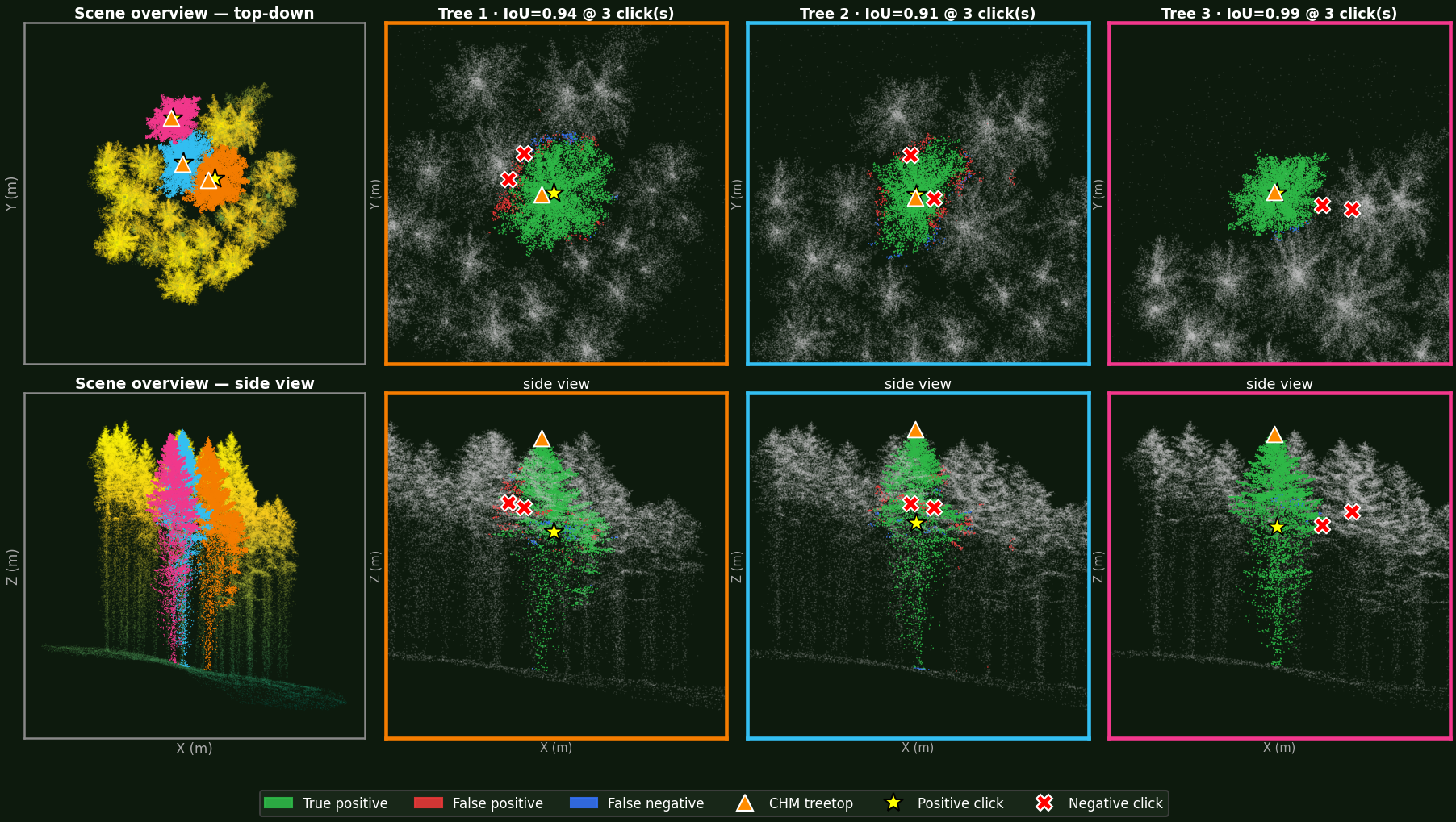
Pre-computed from the test set. Each frame shows top-down view (left) and side view (right).
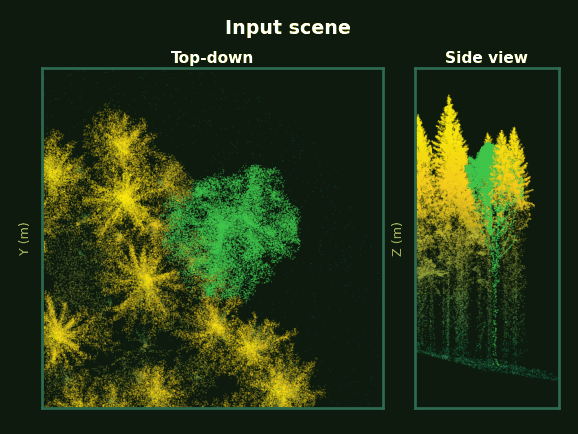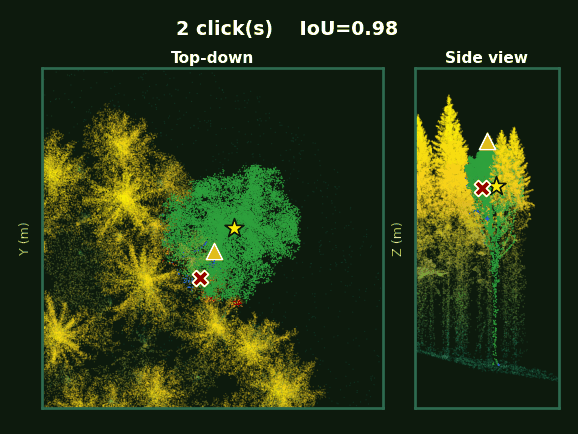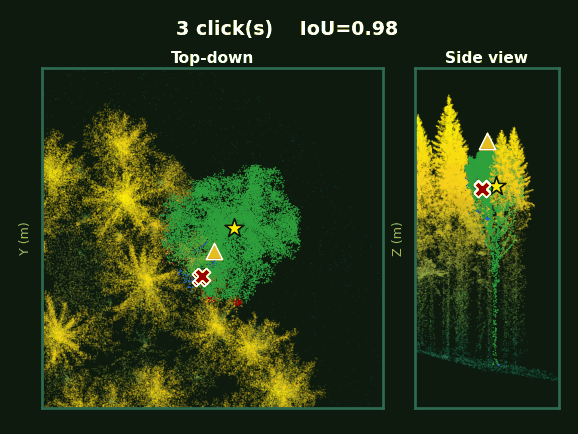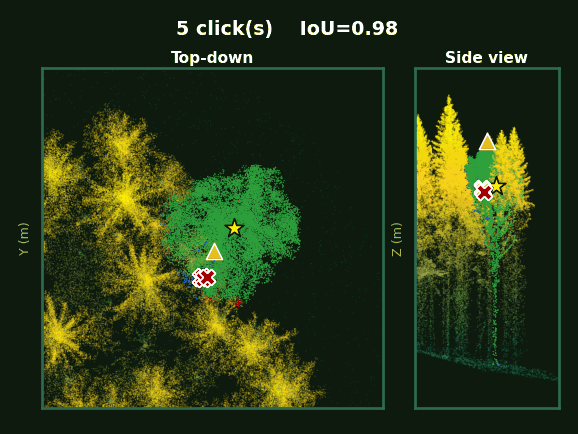
Left: the whole plot with every tree segmented. Right: each tree, rotating, as prompts accumulate from 1 to 5 clicks.

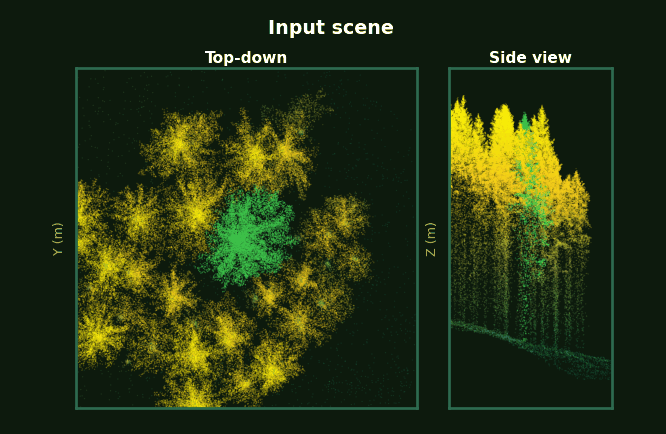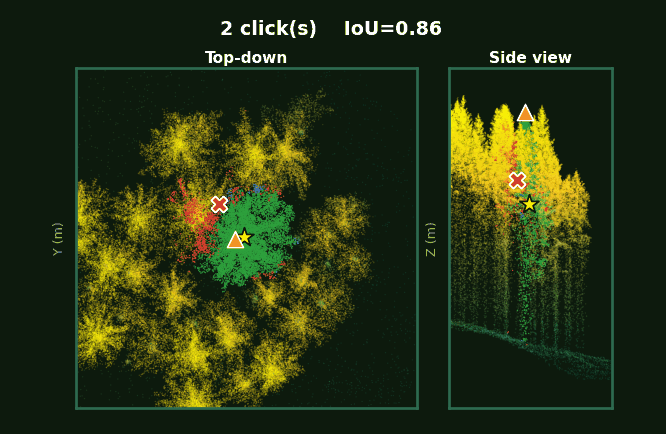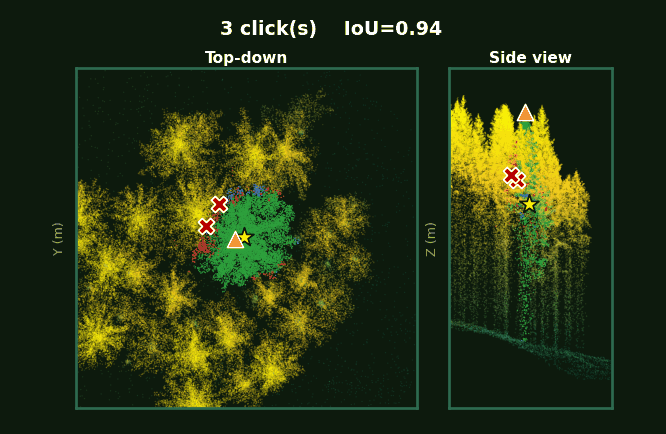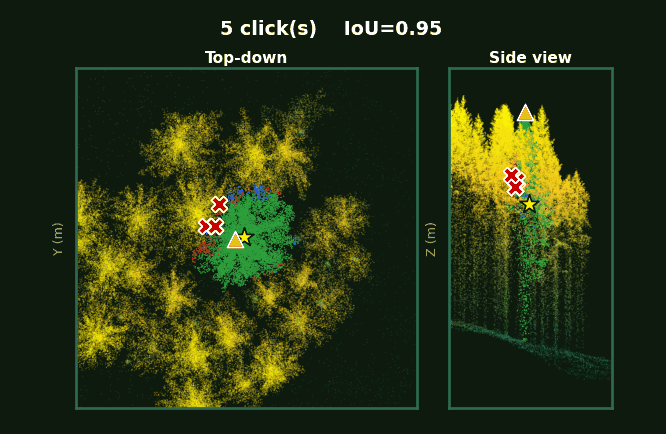


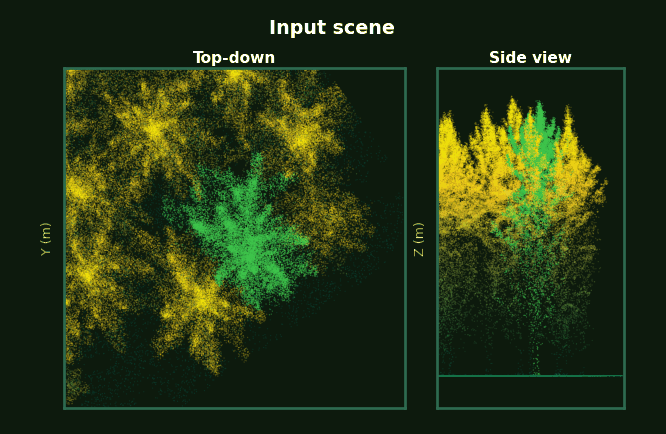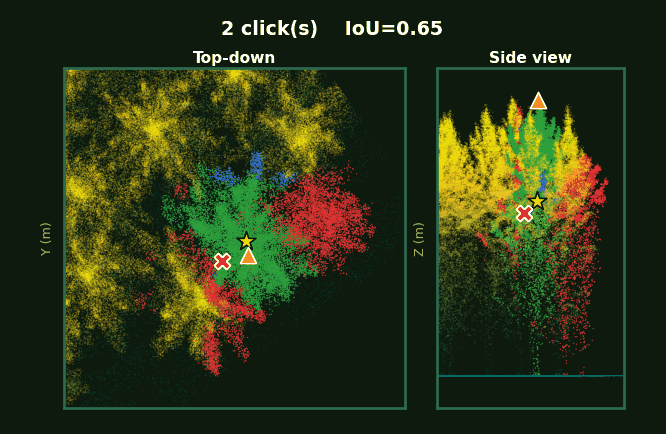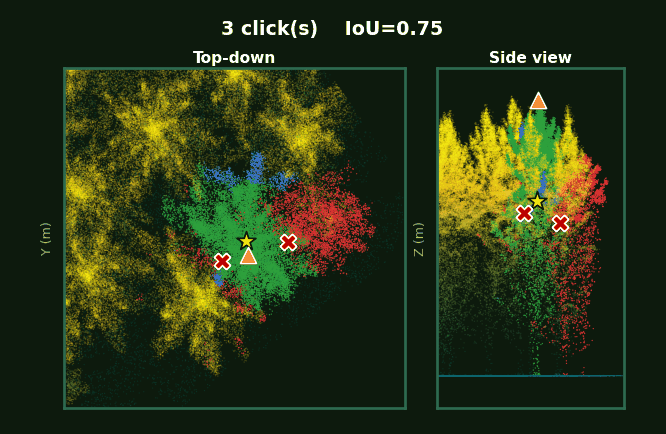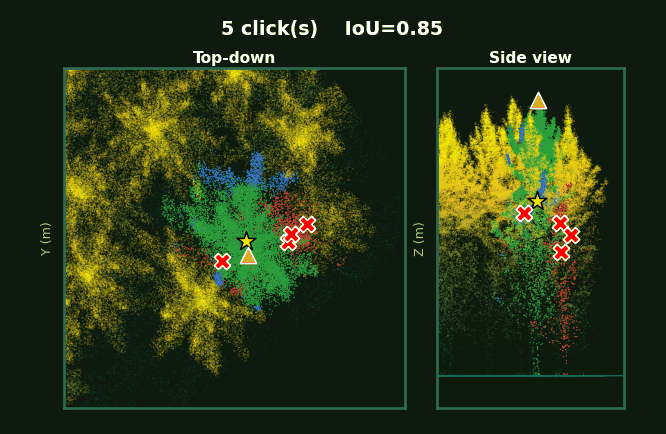
Same scene, same click budget.
Point-SAM

SelectAnyTree Ours
SelectAnyTree turns a structure-aware forest backbone into a promptable instance segmentation model through four stages:
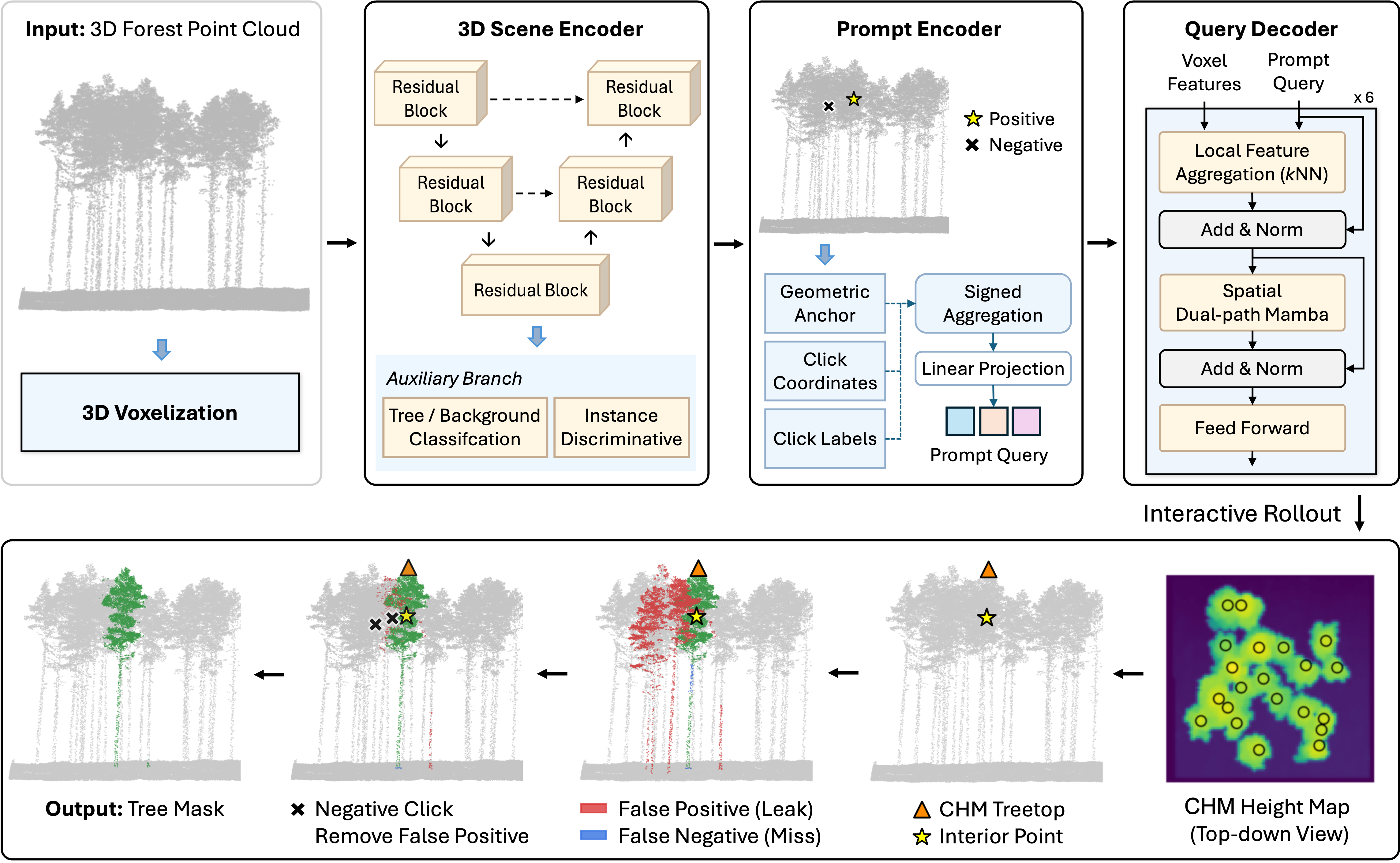
SelectAnyTree architecture. Scene encoding is performed once per plot; prompt encoding and decoding are repeated per click set.
FOR-instanceV2 test set (in-distribution) and LAUTx (cross-dataset generalization, held-out). Bold = best, underline = second best.
GPU wall-clock time (ms) per scene for a k-click session on the FOR-instanceV2 test set.
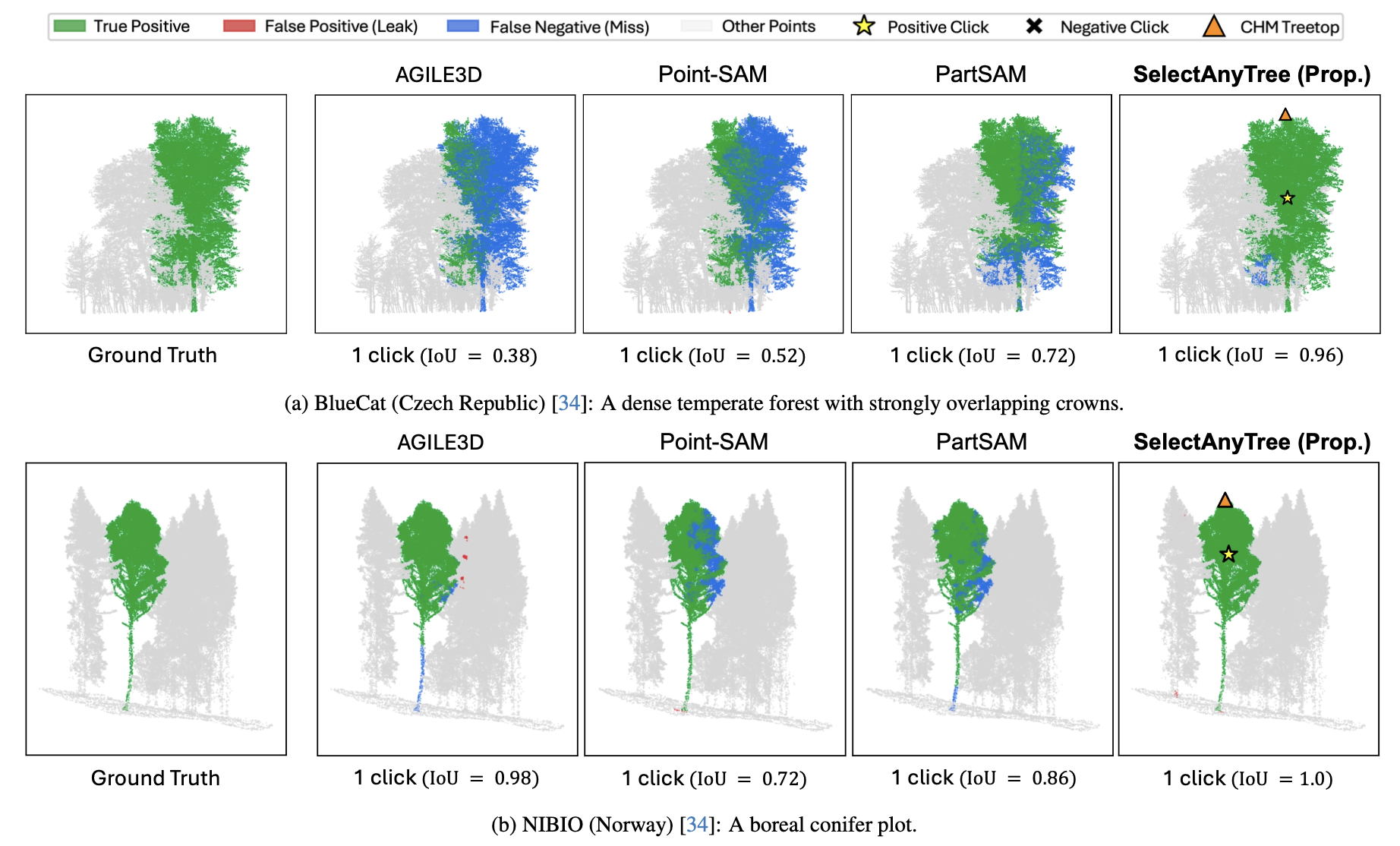
Single-click segmentation compared against promptable baselines on the same target tree.
@article{nguyen2026selectanytree,
title = {SelectAnyTree: A Promptable Instance Segmentation Model for 3D Forest {LiDAR} Point Clouds},
author = {Nguyen, Trung Thanh and Lusk, Daniel and Gerberding, Kilian and Vajna-Jehle, Janusch and Vu, Tuan-Anh and Le, Duc Viet and Vo, Tu and Nguyen, Phi Le and Kawanishi, Yasutomo and Komamizu, Takahiro and Ide, Ichiro and Frey, Julian and Kattenborn, Teja},
journal = {arXiv preprint arXiv:2606.27491},
year = {2026}
}