Trung Thanh Nguyen
🔬 PhD Candidate @ Nagoya University | Student Researcher @ RIKEN

I am a PhD candidate at Nagoya University, specializing in the Department of Intelligent Systems. My research focuses on vision-language models, multimodal recognition, and video captioning, with applications in solving real-world problems.
Currently, I am a student researcher at RIKEN National Science Institute, working on the Guardian Robot Project. My research involves open-world action detection and multi-view multi-modal action recognition by analyzing multimodal sensory data.
Additionally, I am in charge at the Center for Artificial Intelligence, Mathematical and Data Science, collaborating with Japanese corporations to develop practical AI solutions.
📩 Contact: nguyent (at) cs.is.i.nagoya-u.ac.jp
news
| Dec 18, 2025 | I was invited by RIKEN R-CSS to attend the SCA/HPC Asia 2026 and the ACM Asia School on HPC & AI, Japan. |
|---|---|
| Dec 12, 2025 | Our paper “Q-Adapter” won the Best Oral Award at ACM MMAsia, Malaysia. |
| Dec 03, 2025 | I have successfully completed my PhD pre-defense. Onward to the final defense! |
| Nov 11, 2025 | 2 papers — “View-aware Cross-modal Distillation for Multi-view Action Recognition” and “PADM: A Physics-aware Diffusion Model for Attenuation Correction” — have been accepted to IEEE/CVF WACV2026, United States. |
| Oct 21, 2025 | Our paper “Hierarchical Global-Local Fusion for One-stage Open-vocabulary Temporal Action Detection” has been accepted to ACM TOMM (IF: 6.0) journal. |
| Oct 08, 2025 | I was selected as a Rising Star for the Freiburg Rising Stars Academy, Universität Freiburg, Germany. |
| Oct 03, 2025 | I was selected to present my PhD research at the Doctoral Symposium of ACM MMAsia, Malaysia. |
| Oct 01, 2025 | Our paper “Q-Adapter: Visual Query Adapter for Extracting Textually-related Features in Video Captioning” has been accepted to ACM MMAsia, Malaysia. |
| Sep 18, 2025 | Our paper “Multimodal Dataset and Benchmarks for Vietnamese PET/CT Report Generation” has been accepted to NeurIPS, United States. |
| Aug 25, 2025 | I was awarded a research grant from Murata Foundation (est. 1970), Japan. |
latest posts
| Mar 03, 2025 | Presenting at IEEE/CVF WACV 2025 🇺🇸 |
|---|---|
| Dec 06, 2024 | Presenting at ACM Multimedia Asia 2024 🇳🇿 |
| Sep 30, 2024 | Master’s Graduation from Nagoya University 🎓 |
| May 30, 2024 | Presenting at IEEE FG 2024 🇹🇷 |
| Mar 08, 2024 | Data Science Training at North Carolina State University 🇺🇸 |
selected publications
- IEEE/CVF WACV
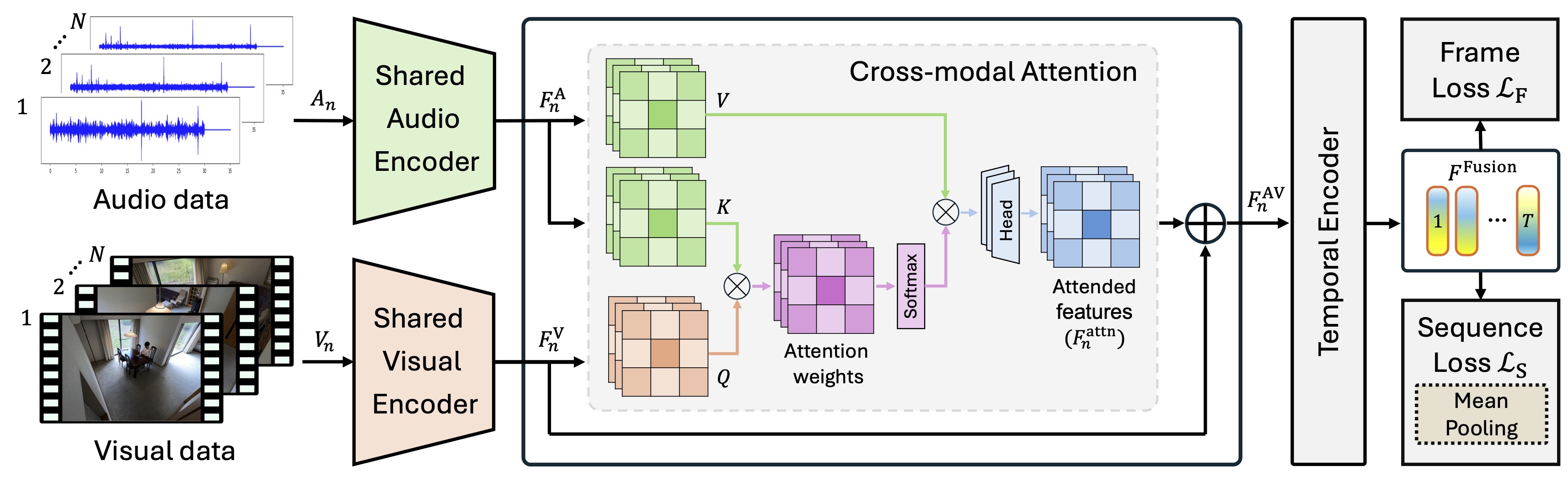 View-aware Cross-modal Distillation for Multi-view Action RecognitionIn Proceedings of the 2026 IEEE/CVF Winter Conference on Applications of Computer Vision, 2026
View-aware Cross-modal Distillation for Multi-view Action RecognitionIn Proceedings of the 2026 IEEE/CVF Winter Conference on Applications of Computer Vision, 2026





